
Introduction
Affinity Propagation (AP) algorithm is a relatively new algorithm that was introduced by Frey and Dueck in 2007. The algorithm is based on the concept of message passing between data points to determine the clustering structure. Affinity Propagation is a clustering algorithm that identifies exemplars within a dataset, representing the most representative data points. Unlike traditional clustering methods where the number of clusters needs to be predefined, Affinity Propagation determines both the number of clusters and their centroids automatically based on similarities between data points. It operates by iteratively exchanging messages between data points to find the most suitable exemplars, considering both similarity and responsibility metrics. This iterative process continues until convergence is achieved, resulting in a set of exemplars that effectively represent the dataset. Affinity Propagation has found applications in various fields such as image analysis, bioinformatics, and natural language processing due to its ability to handle complex datasets and discover meaningful patterns autonomously.
How Does Affinity Propagation Work?
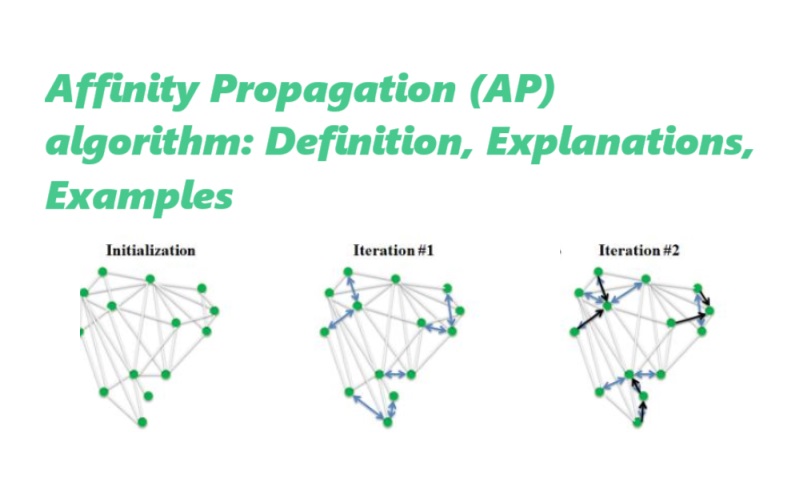
Affinity Propagation does not require the number of clusters to be specified in advance, unlike many other clustering algorithms. Instead, it automatically determines the number of clusters based on the data. The algorithm works by iteratively passing messages between data points to determine the exemplars, which are representative points that best capture the characteristics of each cluster.
The algorithm starts by calculating the similarity between each pair of data points using a similarity measure such as Euclidean distance or correlation. These similarities are then used to update the availability and responsibility matrices, which represent the strength of the connections between data points. The availability matrix reflects the suitability of each point to be an exemplar, while the responsibility matrix reflects the preference of each point to choose another point as its exemplar.
During each iteration, the availability and responsibility matrices are updated based on the messages passed between data points. The algorithm converges when the messages no longer change significantly. The exemplars are then determined based on the availability matrix, and each data point is assigned to the cluster represented by its exemplar.
Advantages of Affinity Propagation
Affinity Propagation has several advantages that make it a popular choice for clustering tasks:
- No need to specify the number of clusters: Affinity Propagation automatically determines the number of clusters based on the data, which can be useful when the number of clusters is unknown.
- Handles complex data: Affinity Propagation can handle complex data with non-linear relationships and does not require the data to be preprocessed or normalized.
- Robust to noise and outliers: Affinity Propagation is robust to noise and outliers in the data, as it considers the entire dataset during the clustering process.
Examples of Affinity Propagation
Let’s consider a few examples to understand how Affinity Propagation works:
Example 1: Suppose we have a dataset of customer preferences for different products. We want to cluster the customers based on their preferences. Affinity Propagation can be used to automatically determine the number of clusters and assign each customer to the cluster represented by their exemplar.
Example 2: Consider a dataset of gene expression levels for different genes. We want to cluster the genes based on their expression patterns. Affinity Propagation can be used to find the exemplars that best represent the gene expression patterns and assign each gene to the corresponding cluster.
Example 3: Imagine a dataset of social media posts from different users. We want to cluster the posts based on their content. Affinity Propagation can be used to identify the exemplars that capture the main themes of the posts and group them into clusters.
Python example code of Affinity Propagation (AP)
Here’s a simple Python example using the Scikit-learn library to implement Affinity Propagation for clustering:
from sklearn.cluster import AffinityPropagation
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, _ = make_blobs(n_samples=300, centers=centers, cluster_std=0.5, random_state=0)
# Apply Affinity Propagation clustering
af = AffinityPropagation().fit(X)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_
n_clusters_ = len(cluster_centers_indices)
# Plot the clusters
plt.figure(figsize=(8, 6))
plt.clf()
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for k, col in zip(range(n_clusters_), colors):
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]]
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col, markeredgecolor='k', markersize=14)
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()This code generates sample data using make_blobs, applies Affinity Propagation clustering to the data, and then visualizes the clusters along with the cluster centers. You can adjust parameters and data according to your specific requirements. Make sure you have the necessary libraries installed (scikit-learn, matplotlib).
Difference between Alternating Projection (AP) Algorithm and Affinity Propagation (AP) Algorithm:
Alternating Projection (AP) Algorithm:
– Objective: Used for pattern synthesis, refining an initial estimate iteratively to meet specified constraints.
– Methodology: Iteratively projects an initial estimate onto convex sets representing constraints until convergence is reached.
– Applications: Signal processing, image reconstruction, antenna design.
– Example: Refining antenna geometry to achieve desired radiation patterns.
Read this article: The AP Algorithm (Alternating Projection) for Pattern Synthesis
Affinity Propagation (AP) Algorithm:
– Objective: Used for clustering, identifying exemplars within a dataset based on similarities between data points.
– Methodology: Determines both the number of clusters and their centroids automatically by exchanging messages between data points.
– Applications: Image analysis, bioinformatics, natural language processing.
– Example: Identifying representative data points in gene expression analysis.
While both algorithms share the “AP” acronym, they serve different purposes and employ distinct methodologies for solving specific problems.
Read here: Alternating Projection vs Affinity Propagation (AP algorithm)
Conclusion
Affinity Propagation is a powerful clustering algorithm that can automatically determine the number of clusters based on the data. It is robust to noise and outliers and can handle complex data with non-linear relationships. By iteratively passing messages between data points, Affinity Propagation identifies exemplars that best represent each cluster and assigns data points to their corresponding clusters. This algorithm has various applications in fields such as customer segmentation, gene expression analysis, and social media clustering.
Suggested: https://iotbyhvm.ooo/explaining-ap-algorithm-affinity-propagation-definition-explanations-examples/